




Dans notre Lors de la dernière plongée dans l'apprentissage automatique, nous avons discuté des différents problèmes qui peuvent survenir avec la classification de texte dans l'apprentissage automatique, et comment les résoudre. Aujourd'hui, nous aimerions appliquer ces différentes théories à un cas d'utilisation. Nous allons étudier comment traiter les problèmes de classification de texte dans le triage des e-mails.
Commençons par une comparaison entre un e-mail et une question dans un chatbot. Typiquement, une question dans un chatbot est très courte :
"Quel temps fera-t-il demain ?"
En revanche, l'intention principale d'un courriel peut être assez cachée, par exemple, lorsque vous transférez un courriel et que vous écrivez dans le corps "fyi". Dans ce cas, le destinataire fait défiler l'e-mail vers le bas et trouve d'abord l'en-tête de l'e-mail précédent, qui est dans le meilleur des cas suivi du corps contenant quelque part l'information principale. Le corps est ensuite généralement suivi d'un long pied de page. S'il s'agit d'un fil d'e-mails, il y aura même plusieurs corps. En bref, pour parvenir au message principal d'un courriel, il faut l'analyser en profondeur. Dans le domaine de l'apprentissage automatique, on parle de prétraitement.
Prétraitement
Le prétraitement des e-mails doit au moins porter sur les points suivants :
- Les fautes d'orthographe
- Synonymes
- Modèles spécifiques aux courriels
- Reconnaissance des entités nommées
Pour obtenir un bon rapport entre l'amélioration des performances du modèle et le temps de prétraitement investi, vous pouvez vous concentrer sur les modèles spécifiques aux e-mails et la reconnaissance des entités nommées.
"Les expressions régulières, ou regex en abrégé, sont un outil extrêmement utile".
Prenons le numéro de sécurité sociale suisse comme exemple d'entité nommée. Ce numéro est toujours composé de 13 chiffres et commence par 756. Si vous entraînez un modèle de reconnaissance d'entités nommées décent avec suffisamment de données, il pourrait bien sûr apprendre que le mot "756.1234.5678.90" est un numéro de sécurité sociale suisse. Une alternative simple à la construction d'un modèle d'apprentissage automatique pour la reconnaissance des entités nommées consiste à utiliser un modèle appelé expression régulière (Regex). À l'aide d'une expression régulière, un courriel peut être considérablement réduit, comme le montre l'exemple des figures 4 et 5.
Figure 4 : Courriel original
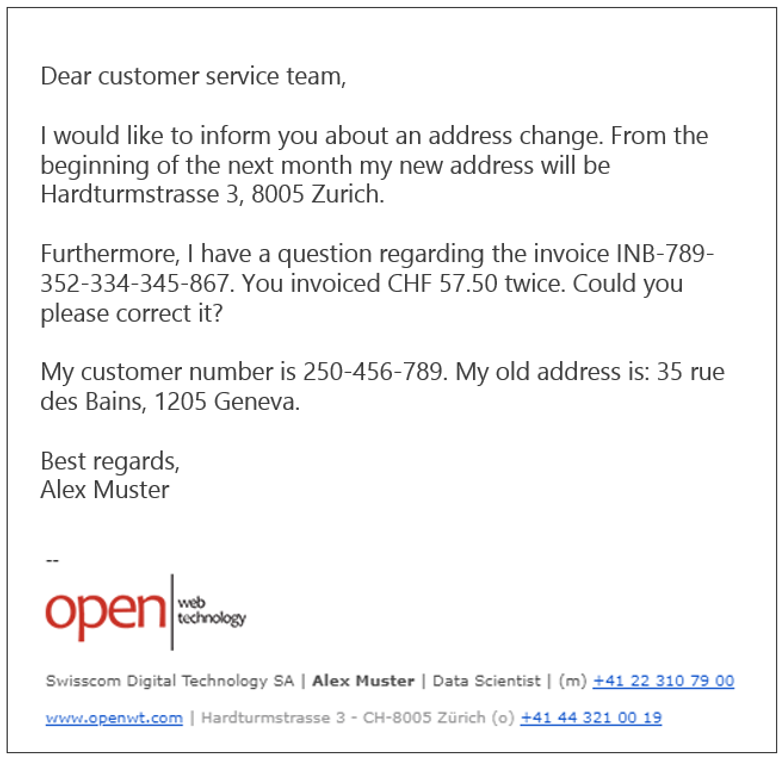
Figure 5 : Courriel prétraité
La détection des adresses postales est un peu plus délicate que la simple utilisation de l'expression rationnelle. Cependant, toutes les autres entités nommées et les motifs de la figure 4 peuvent facilement être traités par des expressions regex.
Construire et entraîner un modèle
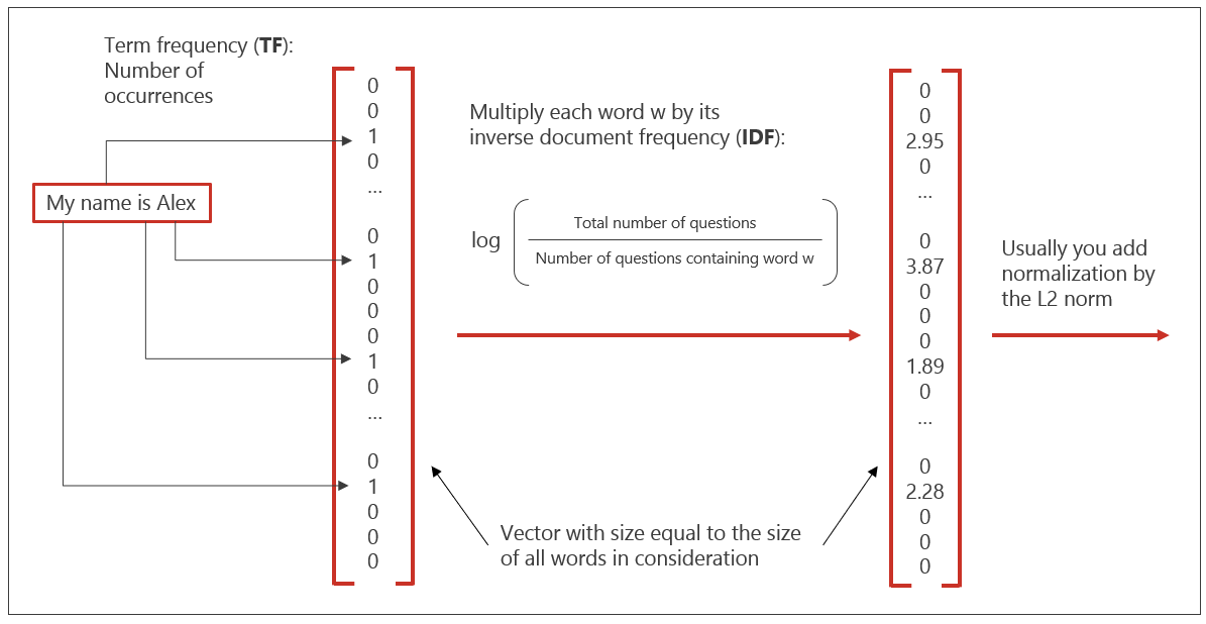
Une fois le texte prétraité, vous devez choisir un modèle pour entraîner le classificateur d'e-mails. Les méthodes basées sur les arbres, comme les forêts aléatoires et les arbres de décision par boosting de gradient, donnent généralement de très bons résultats (en python, voir par exemple randomforest de sklearn, xgboost ou lightgbm). Afin de les utiliser, nous devons transformer le texte d'entrée en vecteurs numériques. Il existe de nombreuses méthodes, comme doc2vec, pour effectuer cette transformation, mais l'une des plus simples et des plus performantes est la méthode dite de fréquence de terme inverse de la fréquence de document TF-IDF (cependant, lorsque l'on utilise des méthodes basées sur des arbres, l'utilité de la partie "IDF" est discutable). Voir la Figure 6 pour une brève explication de TF-IDF que nous avons utilisée sur un corpus de questions de chatbot.
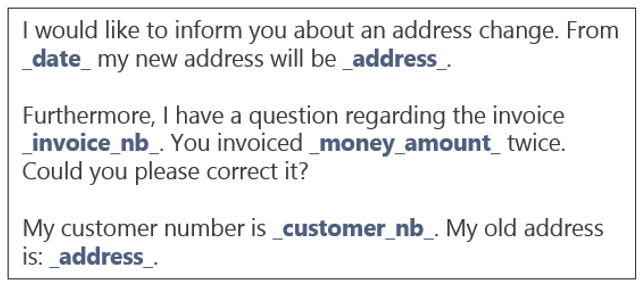
Figure 6 : Comment transformer un texte en un vecteur avec TF-IDF.
Après cette étape, chaque courriel de l'ensemble d'entraînement est représenté par un vecteur numérique. Avec les étiquettes des e-mails représentant les catégories dans lesquelles nous voulons classer chaque e-mail, nous pouvons entraîner le modèle. Dans le cas du triage des e-mails pour un service clientèle, les étiquettes pourraient être "changement d'adresse", "problème de connexion", "question sur le produit", "question sur la facture", "carte de fidélité", etc. Dans la figure 4 ci-dessus, l'e-mail aurait deux étiquettes : "changement d'adresse" et "question sur la facture".
Après avoir construit un premier modèle de classification de texte, vous pouvez améliorer le résultat final en essayant d'autres techniques de prétraitement du texte.
Évaluation du modèle et de la prédiction
Une fois que vous avez construit le modèle, vous devez l'évaluer. Ensuite, si vous constatez que des améliorations sont possibles, retournez à l'étape 1 concernant le prétraitement et recommencez.
"Quelle est la meilleure façon d'évaluer un modèle ?"
La réponse à cette question dépend beaucoup du contexte et des exigences du cas d'utilisation. L'évaluation la plus simple est celle de la précision du modèle. C'est la plus simple à expliquer, par exemple, aux parties prenantes de l'entreprise. Cependant, lorsque les étiquettes ne sont pas distribuées de manière égale, c'est un choix plutôt mauvais. Prenons un exemple extrême comme les cas de détection de fraude où nous pouvons penser qu'une proportion d'un échantillon sur 1000 est une fraude. Si nous prédisons que rien n'est une fraude, alors nous avons une précision de 99,9, ce qui dans ce cas ne veut rien dire. Voici quelques exemples d'autres mesures d'évaluation largement utilisées :
- Cohen-Kappa
- Perte logarithmique ou entropie croisée
- Score F1
- Aire sous la courbe ROC (AUC)
- Précision et Rappel, Sensibilité et Spécificité, notamment.
En particulier, pour le triage des e-mails, il peut être judicieux d'examiner la matrice de confusion du modèle. La figure 7 présente un exemple de matrice de confusion pour le chatbot interne de notre entreprise.
Figure 7 : Matrice de confusion du chatbot interne de notre entreprise.
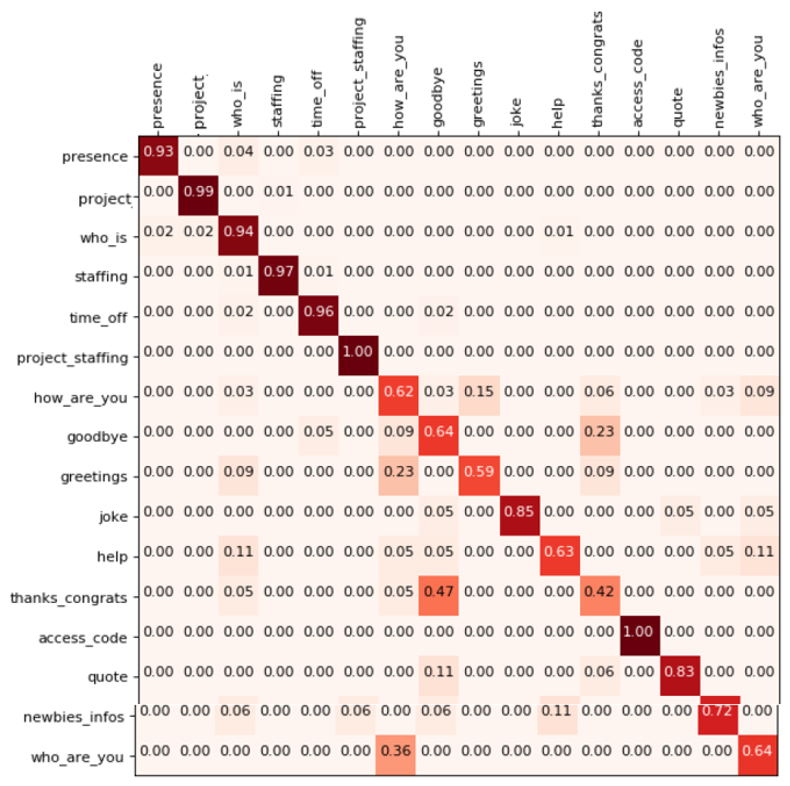
En regardant cette matrice de confusion, vous pouvez voir qu'il y a par exemple quelques confusions concernant les intentions "comment allez-vous ?", "au revoir", et "salutations". Cependant, si l'on demande "quels sont les cas d'utilisation les plus importants pour les employés de l'entreprise", ce ne sont probablement pas ces intents qui ont des objectifs de divertissement mais plutôt des intents comme "qui est Alex", "quelle est ma dotation", "qui est présent/disponible". Ainsi, même si la performance globale du modèle avec l'une des métriques ci-dessus n'est pas très bonne, le modèle peut être très bien optimisé pour le cas d'entreprise réel. Bien sûr, vous pouvez également introduire des pondérations dans les métriques ci-dessus pour répondre aux besoins de l'entreprise. Cependant, la visualisation comme dans la matrice de confusion est un outil très intuitif que tout le monde comprend.
Dans cet aperçu, nous avons passé en revue les principales étapes de la construction d'un modèle d'apprentissage automatique de classification de texte pour le cas d'utilisation du triage des courriels : Le prétraitement du texte, la construction du modèle, l'entraînement du modèle et enfin l'évaluation du modèle. Pour plus de cas d'utilisation sur l'intelligence artificielle, vous pouvez visiter notre page dédiée. Restez à l'écoute pour le prochain aperçu de la technologie Keras !
vous pouvez en savoir plus sur le cas d'utilisation de l'apprentissage automatique : Keras pour la classification de texte


